Context-Free Grammar (CFG)
In the introduction to automata theory, we saw that finite automata recognize
exactly the regular languages. However, many important languages - including the syntax of most programming
languages - have recursive, nested structure that regular languages cannot capture.
Context-free grammars provide a more powerful formalism for describing such languages.
Definition: Context-Free Grammar (CFG)
A context-free grammar is a 4-tuple \((V, \Sigma, R, S)\) where
- \(V\) is a finite set called the variables,
- \(\Sigma\) is a finite set disjoint from \(V\), called the terminals,
- \(R\) is a finite set of production rules, each of the form \(A \to w\) where \(A \in V\) and \(w \in (V \cup \Sigma)^*\),
- \(S \in V\) is the start variable.
Definition: Derivation and Generated Language
Let \(G = (V, \Sigma, R, S)\) be a context-free grammar. For strings \(\alpha, \beta \in (V \cup \Sigma)^*\),
we say \(\alpha\) yields \(\beta\) in one step, written \(\alpha \Rightarrow \beta\),
if there exist \(u, v \in (V \cup \Sigma)^*\) and a rule \(A \to w \in R\) such that
\[
\alpha = uAv \quad \text{and} \quad \beta = uwv.
\]
We write \(\alpha \Rightarrow^* \beta\) if either \(\alpha = \beta\) or there exists a finite sequence
\[
\alpha = \alpha_0 \Rightarrow \alpha_1 \Rightarrow \cdots \Rightarrow \alpha_k = \beta \quad (k \geq 1),
\]
called a derivation of \(\beta\) from \(\alpha\). The language generated by \(G\) is
\[
L(G) = \{ w \in \Sigma^* \mid S \Rightarrow^* w \}.
\]
A language \(L \subseteq \Sigma^*\) is context-free if \(L = L(G)\) for some context-free grammar \(G\).
Example:
\[
\begin{align*}
&X \to 00X1 \, | \, Y01 \\\\
&Y \to $
\end{align*}
\]
In this grammar, \(V = \{X, Y\}, \, \Sigma = \{0, 1, $\}, \, S = X\), and \(R\) is the collection of above rules.
For example, this grammar generates the string \(0000$0111\). The derivation of the string in this grammar is
\[
X \Rightarrow 00X1 \Rightarrow 0000X11 \Rightarrow 0000Y0111 \Rightarrow 0000$0111.
\]
Note: \( X \to 00X1 \, | \, Y01\) means \( X \to 00X1\) OR \(X \to Y01\).
Context-free grammars are strictly more powerful than regular expressions:
every regular language is context-free, but not vice versa. The key advantage is that CFGs can describe recursive
and nested structures.
Consider the language
\[
L_1 = \{0^n 1^n \mid n \geq 0\}.
\]
This language is not regular - no finite automaton can recognize it, because a finite
automaton cannot "count" an unbounded number of 0s and then match them with the same number of 1s.
To prove this rigorously, we use the Pumping Lemma.
Pumping Lemma
The Pumping Lemma is the standard tool for proving that a language is not regular.
The idea is that any sufficiently long string in a regular language must contain a substring
that can be "pumped" (repeated any number of times) while remaining in the language - a
consequence of the pigeonhole principle applied to the finite number of states.
Theorem: Pumping Lemma for Regular Languages
If \(L\) is a regular language, then there exists \(p \in \mathbb{N}\) (called the pumping length)
such that every string \(s \in L\) with \(|s| \geq p\) can be divided into three pieces, \(s = xyz\), satisfying:
- \(\forall i \geq 0, \, xy^i z \in L\),
- \(|y| > 0\),
- \(|xy| \leq p\).
Proof Sketch.
Since \(L\) is regular, there exists a DFA \(M = (Q, \Sigma, \delta, q_0, F)\) recognizing \(L\).
Set \(p = |Q|\). Let \(s = s_1 s_2 \cdots s_n \in L\) with \(n \geq p\), and let
\[
r_0, r_1, \ldots, r_n
\]
be the sequence of states \(M\) visits while reading \(s\), where \(r_0 = q_0\),
\(r_i = \delta(r_{i-1}, s_i)\) for \(i \geq 1\), and \(r_n \in F\).
The sequence \(r_0, r_1, \ldots, r_p\) consists of \(p + 1\) states drawn from \(Q\) (which has only \(p\) elements),
so by the pigeonhole principle two of them must coincide: there exist indices
\(0 \leq j \lt k \leq p\) with \(r_j = r_k\). Define
\[
x = s_1 \cdots s_j, \qquad y = s_{j+1} \cdots s_k, \qquad z = s_{k+1} \cdots s_n.
\]
Then \(s = xyz\), \(|y| = k - j > 0\), and \(|xy| = k \leq p\).
Reading \(x\) takes \(M\) from \(r_0\) to \(r_j\); reading \(y\) takes it from \(r_j\) back to \(r_k = r_j\);
reading \(z\) takes it from \(r_j\) to \(r_n \in F\). Hence for every \(i \geq 0\), reading \(xy^i z\) loops
the cycle \(i\) times before continuing along \(z\), still ending at \(r_n \in F\). Therefore
\(xy^i z \in L\) for all \(i \geq 0\).
To see this concretely, suppose for contradiction that \(L_1\) is regular, with pumping length \(p\).
Choose \(s = 0^p 1^p \in L_1\); since \(|s| = 2p \geq p\), the lemma gives a decomposition \(s = xyz\)
with \(|xy| \leq p\) and \(|y| > 0\). The constraint \(|xy| \leq p\) forces \(xy\) to lie entirely
within the initial block of \(0\)s, so \(y\) consists only of \(0\)s — say \(y = 0^k\) with \(k \geq 1\).
Then \(xy^2 z = 0^{p+k} 1^p\) has more \(0\)s than \(1\)s, hence \(xy^2 z \notin L_1\), contradicting
condition 1 of the Pumping Lemma. Therefore \(L_1\) is not regular.
However, \(L_1\) is context-free. It can be generated by the grammar
\[
S \to 0S1 \mid \epsilon.
\]
Indeed, applying the rule \(S \to 0S1\) exactly \(n\) times followed by \(S \to \epsilon\) yields the derivation
\[
S \Rightarrow 0S1 \Rightarrow 00S11 \Rightarrow \cdots \Rightarrow 0^n S 1^n \Rightarrow 0^n 1^n,
\]
showing every \(0^n 1^n \in L(G)\); a symmetric induction on derivation length confirms \(L(G) \subseteq L_1\).
The recursive rule \(S \to 0S1\) ensures that every 0 is matched by a corresponding 1 — exactly the kind
of nested structure that a CFG can capture but a finite automaton cannot.
Pushdown Automata
The Pumping Lemma showed that finite automata lack the memory to handle languages like \(L_1 = \{0^n 1^n\}\).
To recognize context-free languages, we need a computational model with auxiliary storage.
A pushdown automaton (PDA) extends a finite automaton with a stack -
an unbounded last-in, first-out memory - that provides exactly the right amount of additional power.
Definition: Pushdown Automaton (PDA)
A pushdown automaton is a 6-tuple \((Q, \Sigma, \Gamma, \delta, q_0, F)\) where
- \(Q\) is a finite set of states,
- \(\Sigma\) is the input alphabet,
- \(\Gamma\) is the stack alphabet,
- \(\delta: Q \times \Sigma_{\epsilon} \times \Gamma_{\epsilon} \to \mathcal{P}(Q \times \Gamma_{\epsilon})\) is the transition function,
- \(q_0 \in Q\) is the start state,
- \(F \subseteq Q\) is the set of accept states.
Here \(\Sigma_{\epsilon} = \Sigma \cup \{\epsilon\}\) and \(\Gamma_{\epsilon} = \Gamma \cup \{\epsilon\}\),
matching the convention introduced for nondeterministic finite automata in the
introduction to automata theory.
A transition \((r, c) \in \delta(q, a, b)\) means: from state \(q\), reading input symbol \(a\) (or no input if \(a = \epsilon\))
and popping \(b\) from the top of the stack (or popping nothing if \(b = \epsilon\)), the PDA may move to state \(r\)
while pushing \(c\) onto the stack (or pushing nothing if \(c = \epsilon\)). \(\mathcal{P}(\cdot)\) denotes the power set, reflecting
nondeterminism.
Definition: PDA Computation and Acceptance
Let \(M = (Q, \Sigma, \Gamma, \delta, q_0, F)\) be a PDA and \(w \in \Sigma^*\) an input string.
\(M\) accepts \(w\) if \(w\) can be written as \(w = w_1 w_2 \cdots w_m\) with each
\(w_i \in \Sigma_{\epsilon}\), and there exist a sequence of states \(r_0, r_1, \ldots, r_m \in Q\)
and a sequence of stack contents \(s_0, s_1, \ldots, s_m \in \Gamma^*\) satisfying:
- \(r_0 = q_0\) and \(s_0 = \epsilon\) (the computation starts in the start state with empty stack),
- for each \(i \in \{0, 1, \ldots, m-1\}\), there exist \(a, b, c \in \Gamma_{\epsilon}\) and \(t \in \Gamma^*\)
with \(s_i = bt\), \(s_{i+1} = ct\), and \((r_{i+1}, c) \in \delta(r_i, w_{i+1}, b)\)
(each step follows a valid transition: pop \(b\), push \(c\)),
- \(r_m \in F\) (the computation ends in an accept state).
The language recognized by \(M\) is
\[
L(M) = \{ w \in \Sigma^* \mid M \text{ accepts } w \}.
\]
A PDA is similar to an NFA but can additionally push symbols onto and pop symbols from its stack at each step.
This extra memory allows PDAs to recognize some nonregular languages.
Again, consider the language:
\[
L_1 = \{0^n 1^n \mid n \geq 0\}.
\]
The PDA \(M_1\) reads symbols from the input string as follows:
- As each \(0\) is read, pushes it onto the stack.
- After reading the sequence of \(0\)s, pops a \(0\) off the stack for each \(1\) that is read.
- If reading the string is finished exactly when the stack becomes empty, accepts the string, otherwise rejects the input.
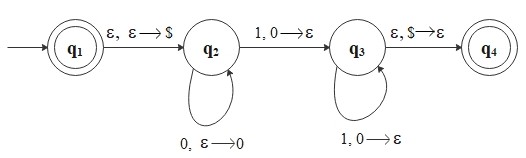
Let's build the state diagram for \(M_1\) that recognizes \(L_1\).
\[
\begin{align*}
&Q = \{q_1, q_2, q_3, q_4\} \\\\
&\Sigma = \{0, 1\} \\\\
&\Gamma = \{0, \$\} \\\\
&F = \{q_1, q_4\}
\end{align*}
\]
Note: A special symbol \(\$\) is used as a bottom-of-stack marker.
The edge labels have the form \(a,\, b \to c\), meaning: read \(a\) from the input, pop \(b\) from
the top of the stack, and push \(c\) onto the stack. For example, \(1,\, 0 \to \epsilon\) means
"read a 1, pop a 0, and push nothing" (effectively removing the 0).
Theorem: CFG-PDA Equivalence
A language is context-free if and only if some pushdown automaton recognizes it.
Proof Sketch.
Both directions are constructive. We describe the constructions but omit the inductive verification
that they preserve the language; only the constructions themselves are given here.
(⟹) CFG to PDA.
Given a CFG \(G = (V, \Sigma, R, S)\), we build a PDA \(P\) that
nondeterministically simulates leftmost derivations of \(G\) — derivations in which, at each step,
the leftmost variable in the current sentential form is the one expanded. The stack holds the suffix
of the current sentential form yet to be matched: \(P\) initially pushes \(S\), then repeatedly does
one of two things on each step. If the top of the stack is a variable \(A\), it pops \(A\) and
nondeterministically pushes some \(w\) such that \(A \to w \in R\) (simulating a derivation step).
If the top is a terminal \(a\), it pops \(a\) and matches it against the next input symbol. \(P\) accepts
exactly when the input is consumed and the stack is empty, which corresponds to a successful derivation
of the input from \(S\).
(⟸) PDA to CFG.
Given a PDA \(P\), we may assume (after a routine normalization) that \(P\)
has a single accept state, empties its stack before accepting, and on each transition either pushes one symbol
or pops one symbol but not both. We then construct a CFG with variables \(A_{pq}\) for each pair of states
\((p, q)\), where \(A_{pq}\) is intended to generate exactly the strings that can take \(P\) from state
\(p\) with empty stack to state \(q\) with empty stack. Production rules are designed to mirror PDA
transitions: if a string causes \(P\) to push some symbol at state \(p\) and pop the matching symbol later
at state \(q\), this is captured by a rule \(A_{pq} \to a A_{rs} b\). The start variable is
\(A_{q_0 q_{\mathrm{accept}}}\).
Moreover, every regular language is context-free, because every regular language
is recognized by a finite automaton, and every finite automaton is automatically a pushdown automaton
(one that simply ignores its stack).
Non-Context-Free Languages
Just as the Pumping Lemma for regular languages lets us prove that certain languages are not regular,
there is an analogous result for context-free languages. This time, a sufficiently long string can be
divided into five pieces, where the 2nd and 4th pieces may be "pumped" together
while the resulting string remains in the language.
Theorem: Pumping Lemma for Context-Free Languages
If \(L\) is a context-free language, then there exists a pumping length
\(p \in \mathbb{N}\) such that every string \(s \in L\) with \(|s| \geq p\) can be divided into
five pieces, \(s = uvxyz\), satisfying:
- \(\forall\, i \geq 0, \quad uv^i x y^i z \in L\),
- \(|vy| > 0\),
- \(|vxy| \leq p\).
Proof Sketch.
Let \(G\) be a CFG generating \(L\). Convert \(G\) to Chomsky Normal Form — a standard
normal form in which every production is either \(A \to BC\) (with \(B, C\) variables) or \(A \to a\)
(with \(a\) a terminal). In Chomsky Normal Form, every parse tree of a non-empty string is a binary tree
whose leaves are terminals.
Let \(b\) be the number of variables in \(G\), and set \(p = 2^{b+1}\). A standard counting argument shows
that any binary tree with at least \(2^{b+1}\) leaves has height at least \(b + 1\), so contains a
root-to-leaf path of length at least \(b + 1\) — hence touching at least \(b + 2\) nodes, so by
the pigeonhole principle at least two of those nodes must be labelled with the same variable,
say \(A\).
Pick the lowest such repetition along the path. Let the upper occurrence of \(A\) be the root of a subtree
deriving the substring \(vxy\), and the lower occurrence be the root of a subtree deriving \(x\);
decompose \(s\) accordingly as \(s = uvxyz\). Because the upper \(A\) generates \(vxy\) and the lower
\(A\) generates \(x\), we may iterate or skip the intervening derivation: replacing the lower subtree
with the upper subtree \(i\) times yields the parse tree of \(uv^i x y^i z\). Hence \(uv^i x y^i z \in L\)
for all \(i \geq 0\), giving condition 1.
Condition 2 (\(|vy| > 0\)) follows because in Chomsky Normal Form a non-trivial \(A\)-subtree cannot
derive only the same string as a strictly smaller \(A\)-subtree without forcing \(v = y = \epsilon\),
and the choice of the lowest repetition rules this out. Condition 3 (\(|vxy| \leq p\)) follows from
bounding the height of the upper-\(A\) subtree by \(b + 1\), giving at most \(2^{b+1} = p\) leaves.
Consider the language
\[
L_2 = \{a^n b^n c^n \mid n \geq 0\}.
\]
This is not a context-free language. Intuitively, recognizing \(L_2\) requires maintaining
two independent counts simultaneously (matching \(a\)'s with \(b\)'s and \(b\)'s with \(c\)'s),
which exceeds the capability of a single stack.
To make this precise, suppose for contradiction that \(L_2\) is context-free, with pumping length \(p\).
Choose \(s = a^p b^p c^p \in L_2\); since \(|s| = 3p \geq p\), the lemma gives a decomposition \(s = uvxyz\)
satisfying conditions 1-3. The constraint \(|vxy| \leq p\) forces \(vxy\) to span at most two of the three
symbol blocks (since each block has length \(p\) and traversing all three would require length \(\geq 2p + 1 > p\)).
There are now two cases:
-
\(v\) and \(y\) each contain only one symbol type. Then \(uv^2 x y^2 z\) increases the
counts of at most two of the three symbols \(a, b, c\) while leaving the third unchanged, breaking
the equality \(n_a = n_b = n_c\) required for membership in \(L_2\).
-
\(v\) or \(y\) contains symbols of more than one type. Then \(uv^2 x y^2 z\) places
symbols out of the required order \(a^* b^* c^*\), again leaving \(L_2\).
Either way, \(uv^2 x y^2 z \notin L_2\), contradicting condition 1. Hence \(L_2\) is not context-free.
Recognizing \(L_2\) requires more computational power than a PDA - it requires a
Turing machine.
Deterministic Pushdown Automata (DPDAs)
Recall that for finite automata, deterministic (DFA) and nondeterministic (NFA) models recognize
the same class of languages. For pushdown automata, however, the situation is different:
nondeterministic PDAs are strictly more powerful than deterministic ones. Some context-free
languages cannot be recognized by any DPDA.
Nevertheless, deterministic context-free languages (DCFLs) - those recognizable
by DPDAs - are of great practical importance. Most programming languages are designed to be
DCFLs precisely so that efficient parsers (syntax analyzers) can be constructed
for their compilers.
Definition: Deterministic Pushdown Automaton (DPDA)
A deterministic pushdown automaton is a PDA \((Q, \Sigma, \Gamma, \delta, q_0, F)\)
whose transition function satisfies \(|\delta(q, a, b)| \leq 1\) for every
\((q, a, b) \in Q \times \Sigma_{\epsilon} \times \Gamma_{\epsilon}\), together with the following
determinism condition: for every \(q \in Q\), \(a \in \Sigma\), and \(x \in \Gamma\),
at most one of
\[
\delta(q, a, x), \quad \delta(q, a, \epsilon), \quad \delta(q, \epsilon, x), \quad \delta(q, \epsilon, \epsilon)
\]
is non-empty.
Note that all four may be empty: when no transition is defined for the current configuration,
the computation halts and rejects. Determinism requires no ambiguity in the next move,
not that a next move always exists.
Note that DPDAs still permit \(\epsilon\)-transitions - the determinism condition requires that
at most one transition applies in each situation, not that every transition must read input and stack simultaneously:
- \(\delta(q, a, \epsilon)\): read input \(a\) without inspecting the stack,
- \(\delta(q, \epsilon, x)\): pop \(x\) from the stack without reading input,
- \(\delta(q, \epsilon, \epsilon)\): neither read input nor inspect the stack.
The language \(L_1 = \{0^n 1^n \mid n \geq 0\}\) from our earlier example is a DCFL - the PDA
we constructed for it is in fact deterministic, since at each step the current state, input symbol,
and top-of-stack symbol uniquely determine the next move.
We have now established the hierarchy
\[
\text{regular languages} \subsetneq \text{DCFLs} \subsetneq \text{CFLs}.
\]
The inclusion regular \(\subseteq\) DCFLs follows by the same idea used earlier for regular \(\subseteq\) CFLs:
a DFA is automatically a DPDA that ignores its stack. This inclusion is strict because \(L_1 = \{0^n 1^n\}\)
is a DCFL but, as we showed using the Pumping Lemma, not regular. The inclusion DCFLs \(\subseteq\) CFLs
is immediate (every DPDA is a PDA), and is strict as well: a classical example separating the two classes is
\[
L_3 = \{w w^{\mathrm{R}} \mid w \in \{0, 1\}^*\}
\]
(palindromes of even length over \(\{0, 1\}\), where \(w^{\mathrm{R}}\) denotes the reverse of \(w\)).
A nondeterministic PDA can recognize \(L_3\) by guessing the midpoint and matching symbols against the stack;
no deterministic PDA can, because no fixed strategy can know when the input has reached its midpoint without
lookahead. We omit the formal lower-bound argument that no DPDA recognizes \(L_3\); it is delicate and beyond
our present scope.
In the next pages, we move beyond context-free languages to the most powerful standard computational model —
the Turing machine — which defines the boundary of
what is computable.